Building a context management system before Claude's Compaction existed
When I was building Threadful a few months ago, one of the hardest parts was keeping long conversations coherent. I ended up designing an adaptive context management system. A few months later, Anthropic launched Compaction and solved the same problem natively. I’ve been tinkering with it lately, and here are my thoughts.
Threadful
Threadful was a Chrome Extension for ChatGPT web where you could branch out from any LLM response into a side thread view, allowing you to have organized and clean chats. Every thread was context-aware, meaning it carried the main conversation context up until that point.
The first, easy and quick solution I implemented was making a summary of the chat up until the part where the branch was opened from. I just wanted something simple to build so I could test the experience and keep moving. But as you can notice, this would soon introduce a challenge. One thing is to summarize 4 pairs or user input and LLM response, and another is 20 pairs.
Actually, one of the reasons I decided to build Threadful was because I used to end up with long conversations, very in-depth explorations into topics I wanted to go deeper into, so this was a frustrating thing for me. I realized that this general-purpose summarization implementation was not going to scale well, or fit all use cases.
What was the signal? Opening a thread from response 25 and waiting 10-15 seconds to start using the thread. Even if you consider this time not too much, and worth it given the benefit you’ll get out of it, this wouldn’t scale well, since the accumulated history would hit the model’s limit and that thread would no longer be useful. UX-wise and performance-wise, it was unacceptable.
I first built it for myself, so how could I accept a bad experience for my own use? I had to start thinking about better alternatives.
An adaptive context management system
Before going into details, I want to emphasize that a good and optimal behavior for the model to summarize things would be to consider key points across the chat, whether it does it automatically or by allowing users to select them to consider them later. Since models are not there yet, I had to do it dynamically/manually. All subsequent decisions were based on a 60%/90% threshold I came up with. I didn’t just invent it out of thin air, it came from iteration. I had tried other numbers but this one made more sense and gave me a really good experience, and especially coherence.
I decided to have three strategies. First, it calculates the context size (total tokens used).
javascript
const totalMainChatTokens = contextHistory.reduce((sum, msg) =>
sum + Math.ceil(msg.content.length / 4), 0
);
const threadTokens = threadMessages.reduce((sum, msg) =>
sum + Math.ceil((msg.userText + msg.llmText).length / 4), 0
);
const totalEstimated = totalMainChatTokens + threadTokens;Then, based on this number, it chooses one of these paths:
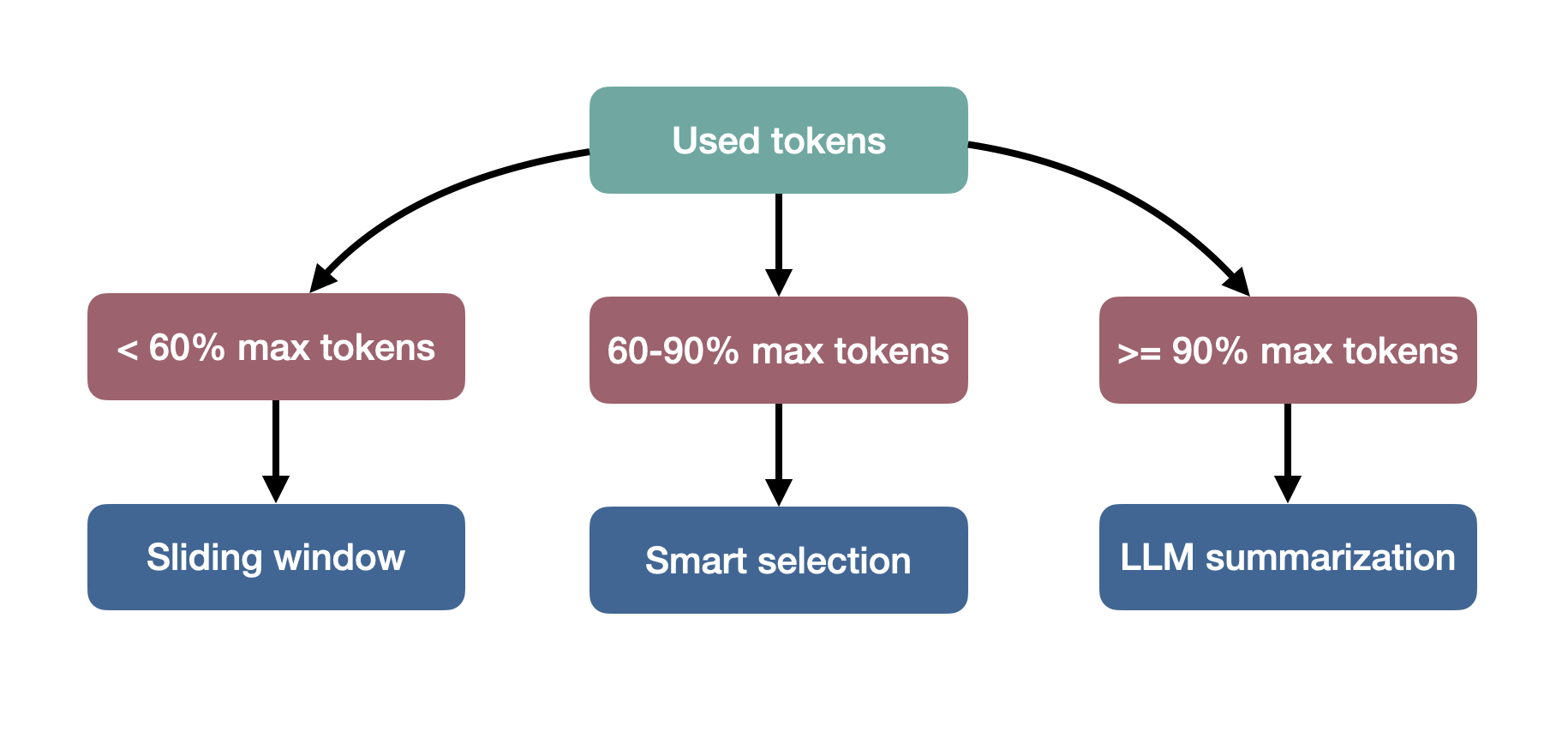
Sliding Window strategy
The most optimal and desirable scenario is when the total context stays below the model’s maximum token limit (ideally under 60%). The Sliding Window strategy will include all the messages from the thread since this is the focus of the conversation. Then it adds the last messages from the main chat as complementary context.
javascript
function slidingWindowContext(contextHistory, threadMessages, newPrompt, model) {
const maxTokens = MODEL_LIMITS[model];
const systemMessage = {
role: "system",
content: "..."
};
function estimateTokens(text) {
return Math.ceil(text.length / 4);
}
function messageTokens(message) {
return estimateTokens(message.content) + 10;
}
let conversationHistory = [systemMessage];
let currentTokens = messageTokens(systemMessage);
const newMessage = { role: "user", content: newPrompt };
const newPromptTokens = messageTokens(newMessage);
currentTokens += newPromptTokens;
threadMessages.forEach(msg => {
if (msg.userText) {
const userMsg = { role: 'user', content: msg.userText };
conversationHistory.push(userMsg);
currentTokens += messageTokens(userMsg);
}
if (msg.llmText) {
const assistantMsg = { role: 'assistant', content: msg.llmText };
conversationHistory.push(assistantMsg);
currentTokens += messageTokens(assistantMsg);
}
});
// Adding main chat context from the end backwards
const reverseContext = [...contextHistory].reverse();
const includedContext = [];
for (const message of reverseContext) {
const msgTokens = messageTokens(message);
if (currentTokens + msgTokens > maxTokens) {
break;
}
includedContext.unshift(message);
currentTokens += msgTokens;
}
conversationHistory.splice(1, 0, ...includedContext);
conversationHistory.push(newMessage);
return conversationHistory;
}Smart Selection strategy
As the conversation grows, and stays in between 60 to 90% of the model’s context window, the Smart Selection strategy comes to play. Here we need to be picky about what to include. It prioritizes relevancy over recency. First, it finds and adds the original answer where the current thread branched from. Then, it includes only the messages around that branching point to preserve the semantic and logical context of the thread. Finally, it includes all messages from the thread.
javascript
function SmartSelectionContext(contextHistory, threadMessages, newPrompt, answerId, model) {
const maxTokens = MODEL_LIMITS[model];
const systemMessage = {
role: "system",
content: "..."
};
function estimateTokens(text) {
return Math.ceil(text.length / 4);
}
// Original response
const originalResponseIndex = contextHistory.findIndex(msg =>
msg.role === 'assistant' && msg.answerId === answerId
);
let conversationHistory = [systemMessage];
let currentTokens = estimateTokens(systemMessage.content) + 10;
// Reserve space for thread messages and new prompt
const threadTokens = threadMessages.reduce((sum, msg) =>
sum + estimateTokens(msg.userText || '') + estimateTokens(msg.llmText || '') + 20, 0);
const newPromptTokens = estimateTokens(newPrompt) + 10;
const availableForContext = maxTokens - threadTokens - newPromptTokens - 1000;
if (originalResponseIndex === -1) {
// If we can't find the specific response, include recent context
console.warn(`Could not find original response with answerId: ${answerId}, using recent context`);
const recentContext = contextHistory.slice(-8); // Last 4 exchanges
recentContext.forEach(msg => {
const msgTokens = estimateTokens(msg.content) + 10;
if (currentTokens + msgTokens < availableForContext) {
conversationHistory.push(msg);
currentTokens += msgTokens;
}
});
} else {
const contextStart = Math.max(0, originalResponseIndex - 4);
const contextEnd = originalResponseIndex + 1;
const relevantContext = contextHistory.slice(contextStart, contextEnd);
relevantContext.forEach(msg => {
const msgTokens = estimateTokens(msg.content) + 10;
if (currentTokens + msgTokens < availableForContext) {
conversationHistory.push(msg);
currentTokens += msgTokens;
}
});
// Add context break indicator if we skipped earlier messages
if (contextStart > 0) {
conversationHistory.push({
role: "system",
content: "[Previous conversation context abbreviated]"
});
currentTokens += 20;
}
}
threadMessages.forEach(msg => {
if (msg.userText) {
conversationHistory.push({ role: 'user', content: msg.userText });
currentTokens += estimateTokens(msg.userText) + 10;
}
if (msg.llmText) {
conversationHistory.push({ role: 'assistant', content: msg.llmText });
currentTokens += estimateTokens(msg.llmText) + 10;
}
});
conversationHistory.push({ role: "user", content: newPrompt });
currentTokens += estimateTokens(newPrompt) + 10;
return conversationHistory;
}LLM Summarization strategy
If the conversation gets really long, to the point of being more than 90% of the model’s context window, then the LLM Summarization strategy is the right choice. It generates a compact semantic summary of the entire main chat history, injects it as a system-level memory, and, just as on the other two, it includes all messages from the current thread.
javascript
async function LLMSummarizedContext(contextHistory, threadMessages, newPrompt) {
const systemMessage = {
role: "system",
content: "..."
};
function estimateTokens(text) {
return Math.ceil(text.length / 4);
}
const conversationSummary = await generateConversationSummary(contextHistory);
let conversationHistory = [
systemMessage,
{
role: "system",
content: `Previous conversation summary: ${conversationSummary}`
}
];
threadMessages.forEach(msg => {
if (msg.userText) conversationHistory.push({ role: 'user', content: msg.userText });
if (msg.llmText) conversationHistory.push({ role: 'assistant', content: msg.llmText });
});
conversationHistory.push({ role: "user", content: newPrompt });
const totalTokens = conversationHistory.reduce((sum, msg) =>
sum + estimateTokens(msg.content) + 10, 0);
return conversationHistory;
}Model capabilities as universal features
When I came across the announcement of Claude Opus 4.6, I was tinkering with agentic tasks. And since you mostly hit the limits here, I noticed you could use this thing called Compaction via the API. I had a mix of feelings.
My first impression was: “Ohh this is so cool. Context management out of the box!“. You no longer need to handle this all by yourself. And then I remembered I had built this before, spending hours testing, deciding tradeoffs, etc. So I thought, if Threadful existed today, this new capability in the model would have either killed my adaptive context system, or, I would have taken advantage of it and use it.
The key takeaway here is that model intelligence capabilities will increasingly permeate almost all tangential features of products existing on the internet. Mine was a tangential feature, not the core, so I would have taken advantage of it.
Threadful core was in the UX and organization, something models are not there yet. Actually, Compaction is not fully there yet. I mean it’s amazing, but looking at its real potential, there are many things to solve. For example, people have been reporting issues like the model forgetting crucial parts of the conversation after it compacts it. Others saying Claude has “dementia“. Wild.
Compaction is automatically handled by the model in the claude.ai interface, and only customizable via Claude Code. But, how many people can or will be willing to use Claude Code to get it working properly? Isn’t the goal to use this technology for the benefit of everyone? AI-human interfaces are a fascinating topic I touched on in this series:
But we’ll get to that point eventually, where every use-case will be covered. A very interesting route to explore this possibility is something called malleable software.
Times to think, then build
If you are working on top of models, and your moat or core feature depends on one of its capabilities, I would really consider changing direction. Stop fighting model capabilities. Embrace them, and instead focus on long-lasting advantages models can't take away. This of course mostly applies for AI startups. If you’re working on research, this might not be a problem at all, but a leverage.
For example one of the untouched territories models haven’t landed yet are interfaces. I’m totally convinced you have a very particular workflow when interacting with AI chat interfaces. You wish you were able to x, y, or z, but you can’t since what you see is what you get, your limited to these general-purpose interfaces these companies provide.
But, what if you know really well a specific use case from your work, an integration, or you have data that is stuck and disperse across different apps? There you go! Leverage these model capabilities and build it for you and your team.
Embrace it, and be malleable
These are fascinating times. Personally, yes, it’s a bit of a strange feeling when you spend hours thinking, designing and building something that the model will later eat. The pain is temporary, and it’s fine, it means an opportunity to grow, adapt, and keep moving. Just as software will become malleable based on our intent, we must also be malleable with how intelligence changes the workings of our current world structure.